LAVIS (Learning and Visual Systems)
DeepCA (Deep Content Analytics)
DeepCA featured on sergroup.com
Friday, August 20, 2021 - Dirk Krechel, Adrian UlgesWe're happy to point you to a recent interview that DeepCA's co-PI, Prof. Dr. Dirk Krechel, has given to our partner SER Group, on sergroup.com. This is where you can find more about our perspective on how new impulses from AI research can benefit content analytics by analyzing unstructured data. Also, find out about tackling challenges such as little training data and integrating technology into practitioner's workflows. Enjoy the read!
Easing Deployment of AI Models for Information Extraction in the Technical Service
Friday, April 02, 2021 - Markus Eberts, Adrian UlgesBuilding AI models for real-world industrial applications comes with special requirements regarding the subsequent deplyoment and integration of the model, typically by non-AI-experts. In cooperation with our DeepCA application partner Empolis, we developed an information extraction service for the detection of machine parts and their error symptoms described in technical service tickets. Consider the following service ticket:
Our model jointly extracts machine parts ("Z-Achse", "Bohraggregat"), their types ("Z-Achse" -> "Mechanical") as well as mentioned error symptoms ("Precision" and "Temperature"). This has applications in the construction of knowledge graphs for new domains ("Which machine parts exist and what failures usually happen?") and the search for related problems and their solutions by technical experts ("Which service tickets contained "Precision" failures of the "Z-Achse"?).
We use the Transformer-Type network BERT as our model's core. BERT is a language model that is pre-trained on a vast amount of unlabeled data to capture semantic and syntactic properties of natural language. We adapt BERT to the target domain by finetuning it on unlabeled data (the service tickets) and then solve the detection of machine parts using a span-based approach, while we classify error symptons on sentence-level.
To ease deployment and (re-)training of our model, we have developed an information extraction service. The service can be integrated into existing software environments via an HTTP interface and internally stores trained models for various domains. New models can be created by specifying the types of machine parts and error symptoms of the respective domain. Training as well as prediction is then performed by sending (labeled) sentences in a JSON format. Here both operations are performed asynchronously and allow for later retrieval of results to account for long runtimes in case of big data. Moreoever, the service can be configured to distribute the workload onto different devices (CPU and GPUs), e.g. to support simultaneous training and prediction.
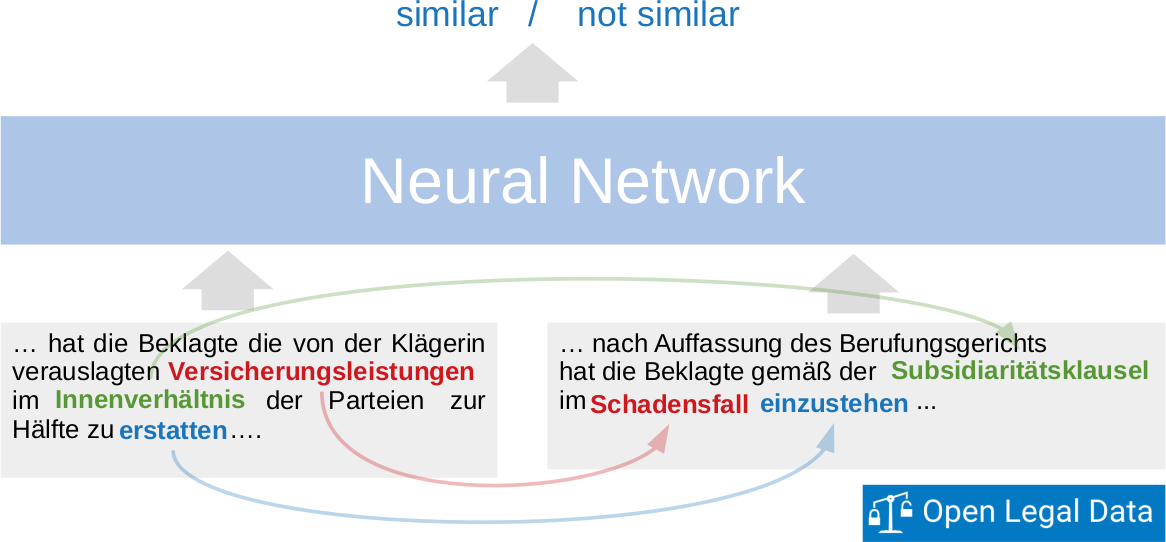
A Dataset for Semantic Similarity in Legal Documents
Tuesday, March 23, 2021 - Marco Wrzalik, Dirk Krechel, Adrian UlgesThe past decade has seen various efforts to make legal documents in German language available to the public. Platforms such as Open Legal Data or OpenJur give free online access to thousands of legal documents. To help users find relevant information, keyword-based search functions are provided. These identify target documents based on a rough topical match, but leave the interpretation of the target document and the localization of specific arguments or claims to the user. There is no support in finding paraphrased equivalents of certain statements in other documents.
Recently, deep neural networks have shown potential in modeling such semantic similarity. However, a certain amount of training examples demonstrating the targeted behavior are needed to achieve well generalizing models, and the ground truth for these training examples is often difficult to produce. In many cases, ground truth can only be obtained through human annotators. This is particularly costly if the annotators have to be experts, as it is the case in the legal domain. If the acquisition of human generated annotations is infeasible, weakly supervised training might be an option: Instead of real ground truth, imperfect proxy data can be used, generated on the basis of heuristics, traditional methods, or combinations of both.
To this end, we contribute the dataset "German Legal Sentences" (GLS) for weakly supervised training of neural similarity models in German-speaking legal documents. GLS has been extracted from the Open Legal Data corpus of over 200,00 German court rulings, using citation parsing: Two passages from two different rulings are assumed to be semantically related if (a) they cite the same law/paragraph or ruling, and (b) their rulings show an overall resemblance in citations and text. From those we generate over 1.5 million sentence pairs for training and testing semantic similarity models.
The dataset, including the citations we parsed for the semantic sentence matching, can be accessed via Github or Hugginface Datasets.

Legal Text Search with Transformers
Wednesday, July 15, 2020 - Marcel Lamott, Marco Wrzalik, Adrian Ulges, Dirk KrechelSearching legal documents is a prominent application for information retrieval: Frequently, legal experts search past court rulings for arguments supporting a certain legal position, and then transfer the argument to the situation at hand. This makes lawyers heavy users of text search, for which search engines such as juris.de offer well-established keyword matching. After this, the lawyer analyzes the target documents manually. Here, keyword search suffices to discover whether a ruling matches the general topicality of interest, but does not directly guide the user to the argument: Finding out whether a text passage supports a certain argument depends on paraphrasing, sentence construction, etc. Consider the following two sentences from two rulings:
vs.
Though the sentences share little term overlap, they are semantically equivalent. To make text search robust to these effects and support legal experts with retrieving arguments, we have trained a neural model for legal search. The model allows whole-sentence queries such as above and retrieves semantically similar sentences. Our basis are documentations of more than 100,000 German court rulings downloaded from Open Legal Data. Each contains citations of other rulings or journals. We utilize this citation network to derive matching passage pairs: Two passages from two different rulings are assumed to contain the same argument if (a) they cite the same law/paragraph, and (b) their rulings show an overall resemblance in citations and text. From this silver standard, we derive our training and validation data for passage retrieval. We apply a BERT-based cross-encoder architecture using the German BERT from Deepset.ai as a reranker for top documents retrieved by a keyword search. Our model outperforms a BM25 baseline quantitatively, and a preliminary end user test indicates that the model's capability for semantic sentence matching is very much appreciated by experts.
Check out our web demo (password access can be requested at adrian dot ulges at hs minus rm dot de).
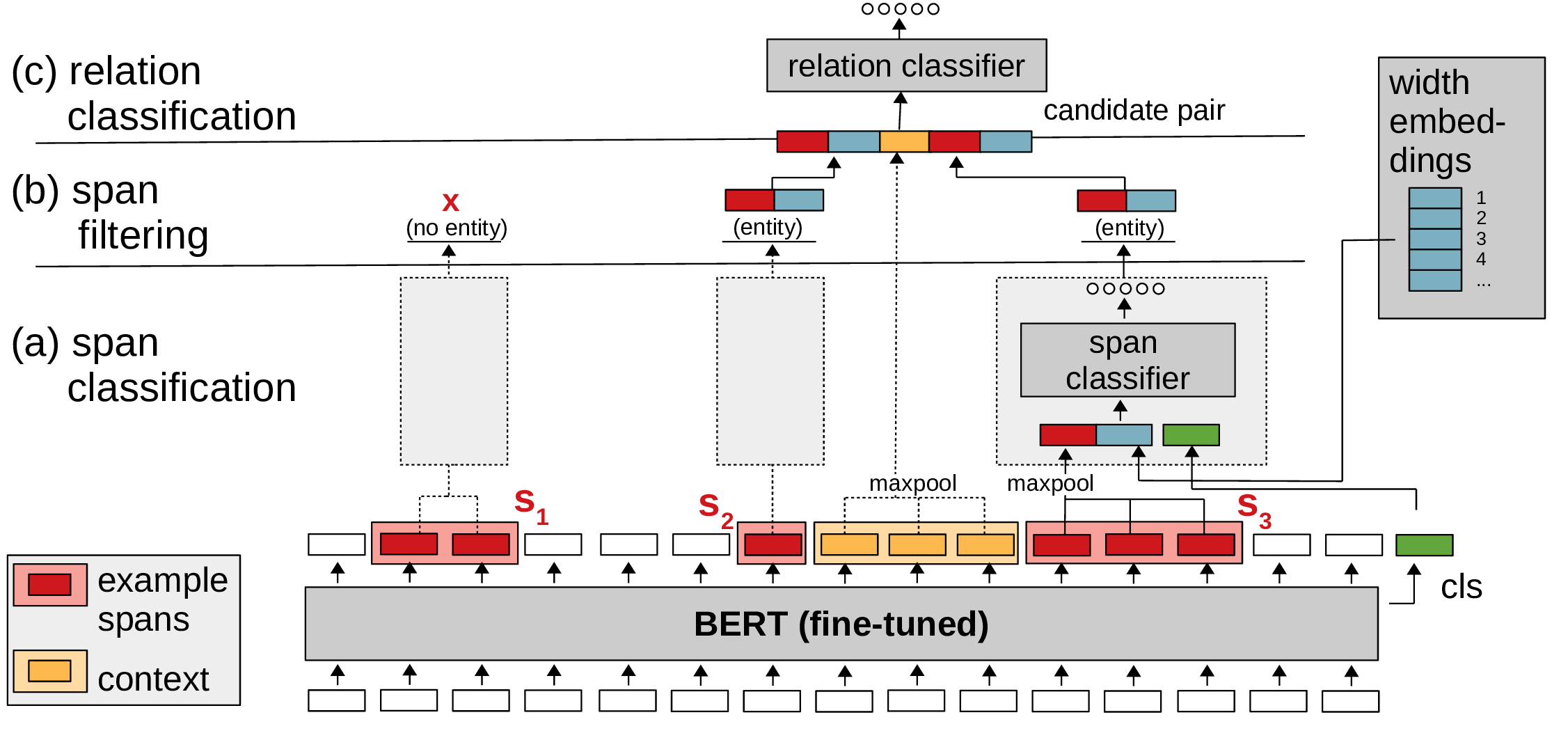
Span-based Joint Entity and Relation Extraction with Transformer Pre-training
Monday, December 23, 2019 - Markus Eberts, Adrian Ulges
The extraction of entities and their relations is one of the key requirements for machine language understanding.
Since the knowledge of entities can provide a strong hint for possible relations and the knowledge of relations can be important for recognizing entities,
current models are trained to jointly predict
the goal of "joint entity and relation extraction" is to extract any entity and their type (e.g. "Shaun of the Dead" [Movie], "Horror Comedy" [Genre] or "Edgar Wright" [Person])
as well as the relations expressed between pairs of entities, such as ("Shaun of the Dead", Genre, "Horror Comedy") or ("Shaun of the Dead", Director, "Edgar Wright").
We present
In experiments on three common joint entity and relation extraction datasets (CoNLL04, ADE and SciERC)
For more details, check out our GitHub repository.
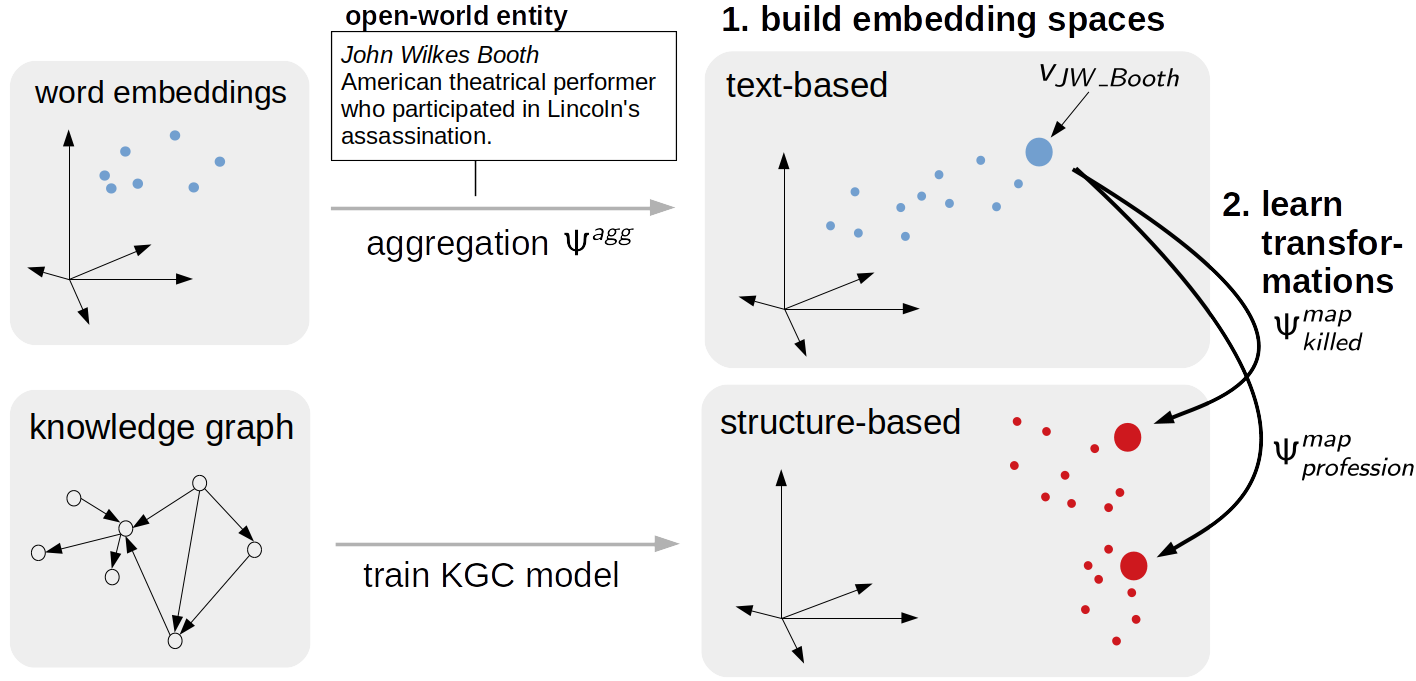
Open-world Knowledge Graph Completion
Friday, December 13, 2019 - Haseeb Shah, Johannes Villmow, Adrian Ulges
Knowledge graphs are an interesting source for disambiguation and discovery in various tasks such as question answering and search. For example, the answer to "Who murdered Abraham Lincoln" may be found as an edge (or triple) in a knowledge graph.
We address the fact that knowledge graphs – which are acquired manually – are often missing crucial facts. Particularly, inserting
We suggest a model for such
From this textual information, a representation (or
Hamming Embeddings for Document Similarity
Tuesday, September 17, 2019 - Felix Hamann, Adrian UlgesThe broad area of Information Retrieval is concerned with devising and implementing systems to retrieve textual information from (usually) large collections of documents. We are interested in returning whole fitting documents from a document collection. A user (be it human or machine) that uses such a system queries either with some text or full documents and receives an ordered collection of candidate documents ranked by their relevancy to the query.
The key challenges here are twofold: The first is the scale on which these systems operate. It is not unusual to be confronted with document collections with millions of candidate documents. The second one concerns the ranking of the documents in the result list. Both recall and precision of the system have to be optimised to make it effective. If the recall is low (not many relevant documents are found at all), much potentially important information is never revealed to the user. If the precision is bad (found relevant documents are not ranked highly), a user has to manually filter out the unimportant documents.
Many approaches to determine the semantic similarity of text
documents have been developed over the last
decades. Traditionally, so-called vector space models are
employed for this task. Here, statistical information about
word occurrences is utilized to map documents to fixed sized
vectors. These vectors are weighed by the counts of respective
words (the
Tackling the problem this way is a quite successful strategy. There are some challenges though: It is usually not very robust against spelling errors and using word identity without any further processing leads to huge vocabularies for phonetically rich languages (such as German) and a missing link for semantical relatedness between inflections, paraphrases and synonyms. Advances in neural approaches for Natural Language Processing lead to dense vectorial representations for words, sentences and documents where semantic relatedness is encoded as a spatial property (the vectors of close words are close in the embedding space).
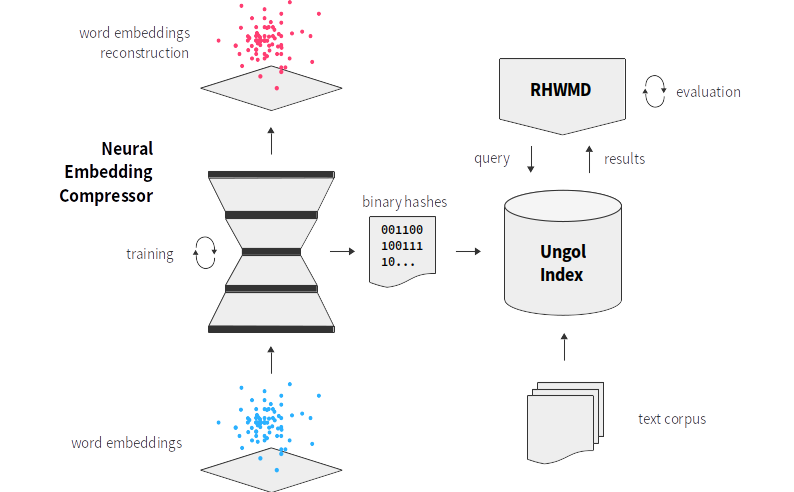
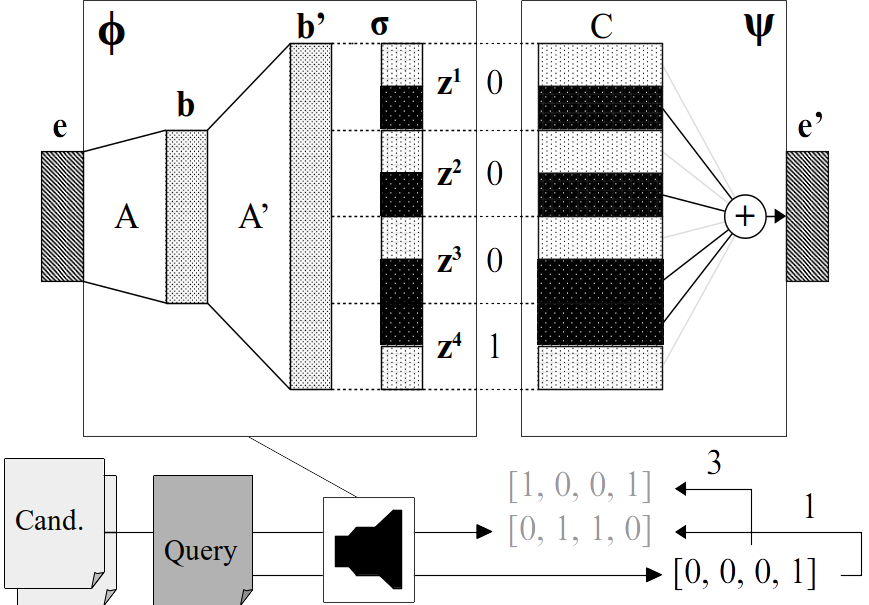
We have utilized a neural encoder-decoder model to map these vectors into Hamming space (i.e. produce binary hash codes) and researched whether their spatial properties are retained. We then formulate a similarity measure on the hash codes and evaluate how well they are suited to solve information retrieval tasks. My Master's Thesis is concerned with embeddings on word-level and implementing a document similarity measure based on the Word Mover's Distance. A follow up paper is concerned with information retrieval using paragraph and document embedding vectors.
Embedding-based and Hybrid Entity Linking
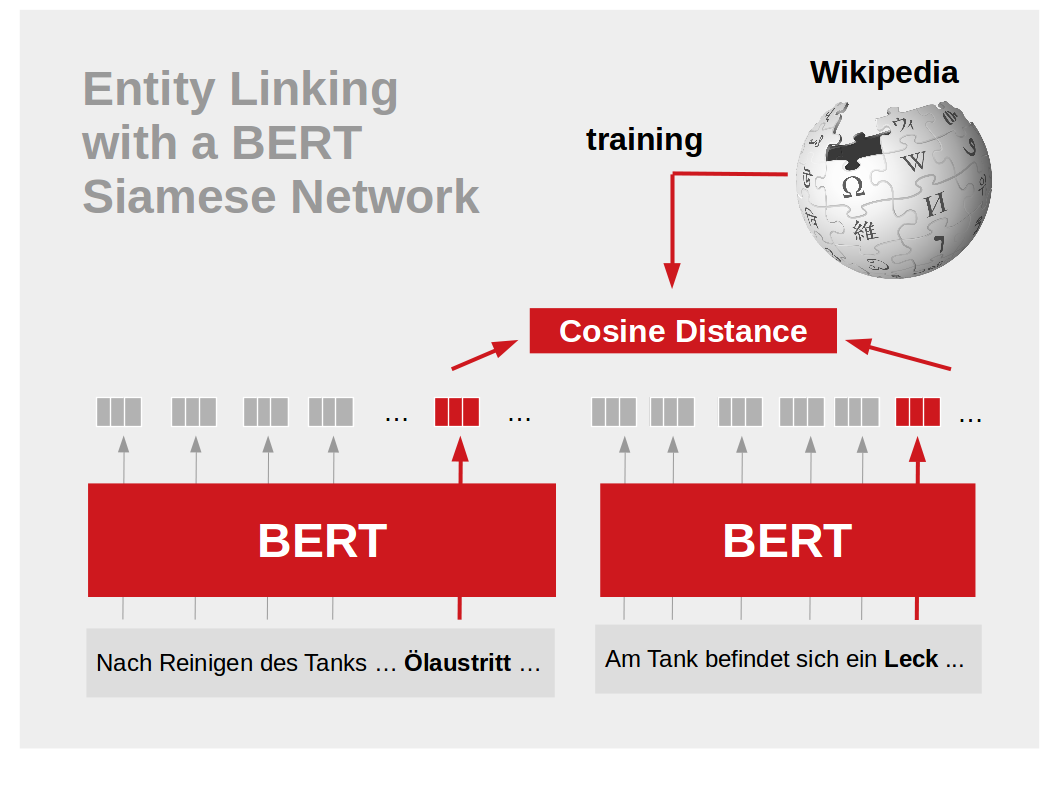
Friday, September 6, 2019 - Nadja Kurz, Felix Hamann, Adrian UlgesA key challenge when making sense of text is to discover known entities (such as Donald_Trump). The challenge of matching textual mentions - which can be abbreviated ("DT"), misspelled ("Trumpf..."), synonyms ("the president", "the white house"), coreferences ("he"), etc. - to entities is referred to as entity linking.
Some of the above cases can be covered using rule-based approaches or fuzzy string matching. For others ("the white house" -> "Donald_Trump"), the meaning of a mention must be inferred using context, i.e. based on the fact that entity and mention tend to appear in similar sentences. This allows us to learn a similarity metric from large text corpora.
We have developed a hybrid entity linking system: Simple cases are covered with a rule-based fuzzy string matching. For challenging cases, we use a neural network-based string similarity: Our model uses BERT (Devlin et al. 2018) in a siamese network, which models a similarity function between the mention and known appearances of entities in reference sentences. The model learns its similarity function from the Wikipedia hyperlink structure.
We have created our model in cooperation with the DeepCA application partner Empolis: For Empolis' knowledge engineering, we discover synonyms for machine parts and faults (such as "leakage" or "cutting shaft") in large collections of issue descriptions.